Yongzhi
Team Leader, Senior Machine Learning Engineer, and Applied Researcher with 13 years of combined experience across top-tier industry and academia. Proven track record of shipping scalable AI, including five high-impact products for TikTok and CapCut that reached billions of users (2022 ByteDance-Style Award). Formerly the Team Lead for Gaming Scene-AIGC at Tencent (2023 Sole Outstanding Performance). Currently leading the development of a world-class, fully AI-driven moderation system for TikTok Live, leveraging MLLMs, SFT, and RL to achieve super-human accuracy for billions of global users.
Tiktok live content moderation using MLLM
Background:
Our team of 12 engineers was tasked with building an automated AI moderation system to fully replace human reviewers within one year. The scope was massive: we needed to cover 90 different content policies. We faced a major architectural conflict:
- OPOM (One Policy One Model): Safe, isolated, but maintenance-heavy.
- AIO (All In One): Scalable, efficient, but high technical risk and unproven generalization.
Objective:
The goal was 100% automation before the deadline. Initially, the group voted for OPOM to minimize short-term risk. I had strong reservations because I foresaw scalability issues, but I practiced ‘disagree and commit.’ I aligned with the team’s decision to start with OPOM, while assigning myself to monitor the efficiency metrics.
Development:
- Identifying the Bottleneck: While implementing OPOM for the first 2 months, I validated my concerns. The process was incredibly labor-intensive; repetitive feature engineering for each policy meant we would mathematically miss the deadline due to linear scaling costs.
- Proposing a Strategic Pilot (The Pivot):
- I didn’t just argue theoretically. I proposed a hybrid strategy to leadership: Keep 10 engineers on the ‘safe’ OPOM path to ensure coverage for top policies, but allow me to lead a small ‘strike team’ (myself + 1 engineer) to pilot the AIO solution on 20 long-tail policies.
- This reduced the project risk while allowing me to prove the concept.
- Navigating Ambiguity & Perseverance:
- The first 3 months of AIO were brutal. Progress was slow due to the lack of foundational infrastructure for multi-task learning.
- Despite the pressure and lack of immediate results, I insisted on building a robust shared architecture rather than quick hacks. I focused on solving the ‘negative transfer’ issues between policies.
Results:
- The Inflection Point: By month 4, our progress accelerated exponentially. My 2-person team launched 10 policies in one month, outpacing the larger team.
- Adoption: Seeing the efficiency, the rest of the team migrated to my architecture. I became the key Technical Owner for the entire project.
- Business Impact: We not only met the deadline but saved over 50% of GPU resources. Without this AIO architecture, we would have physically run out of compute capacity and failed the project.
The pipeline of project All-in-one (AIO) AIM

The methodology of project All-in-one (AIO) AIM

Policy decoupling using Multi-head architecture

Policy decoupling using Multi-Lora architecture

Sketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User’s Casual Sketches

3D scene generation using panoramic RGBD diffusion models

RGBD diffusion


Dense 3D reconstruction and scene understanding for VR headset
Tencent, Canberra Australia
Senior researcher in computer vision, Team lead of Mixed Reality (MR) group
- Roadmap of MR: I have designed the first roadmap of MR for Tencent XR AU-Lab based on a comprehensive evaluation of SOTA methods in stereo depth, multi-view stereo(MVS) and depth fusion.
- I proposed a pyramid and structural-aware plane-sweep MVS approach, based on SimpleRecon, that achieves a speed improvement from 75ms to 25ms.
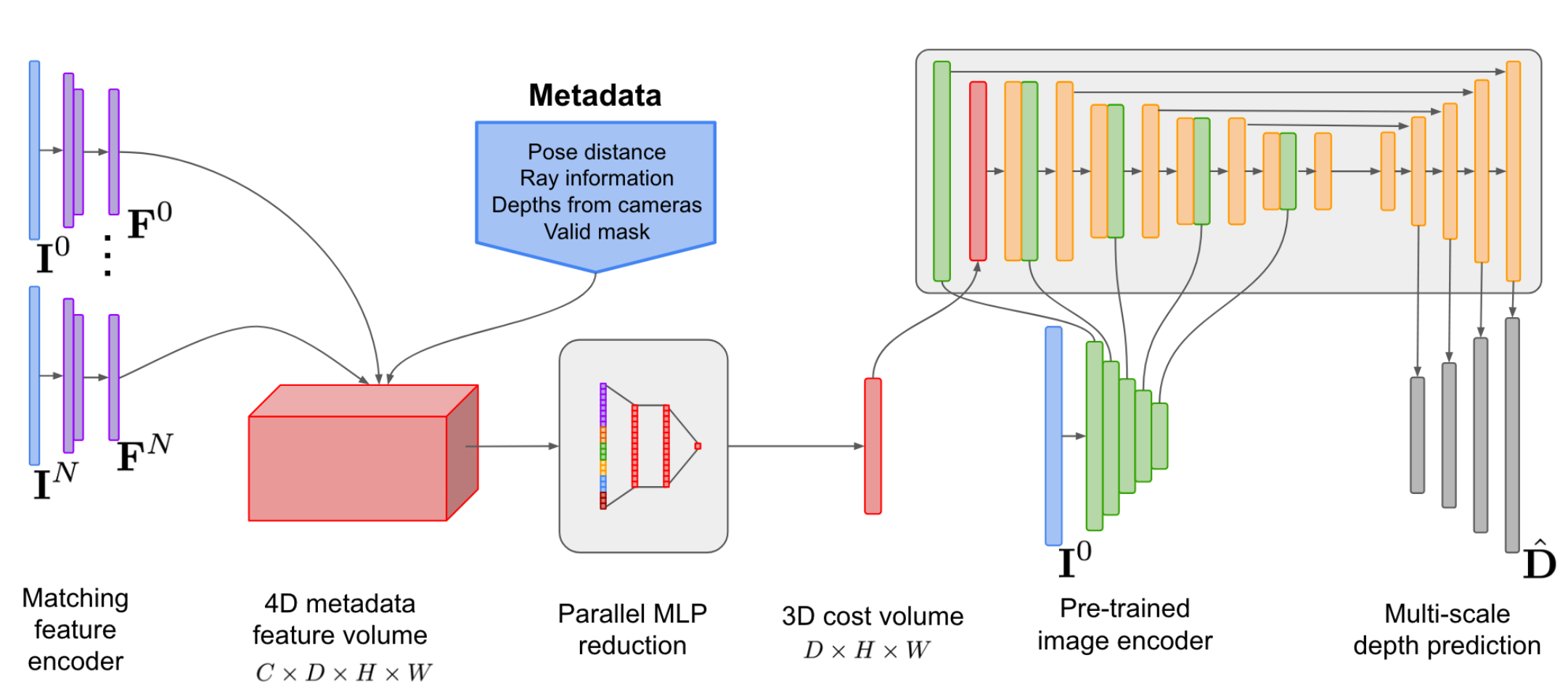 |
 |
- 3D scene understanding: I am leading the development of a 3D scene understanding system similar to Apple’s RoomPlan for MR, which detects 3D objects real-time from RGB-D images.
 |
 |
 |
General plan detection
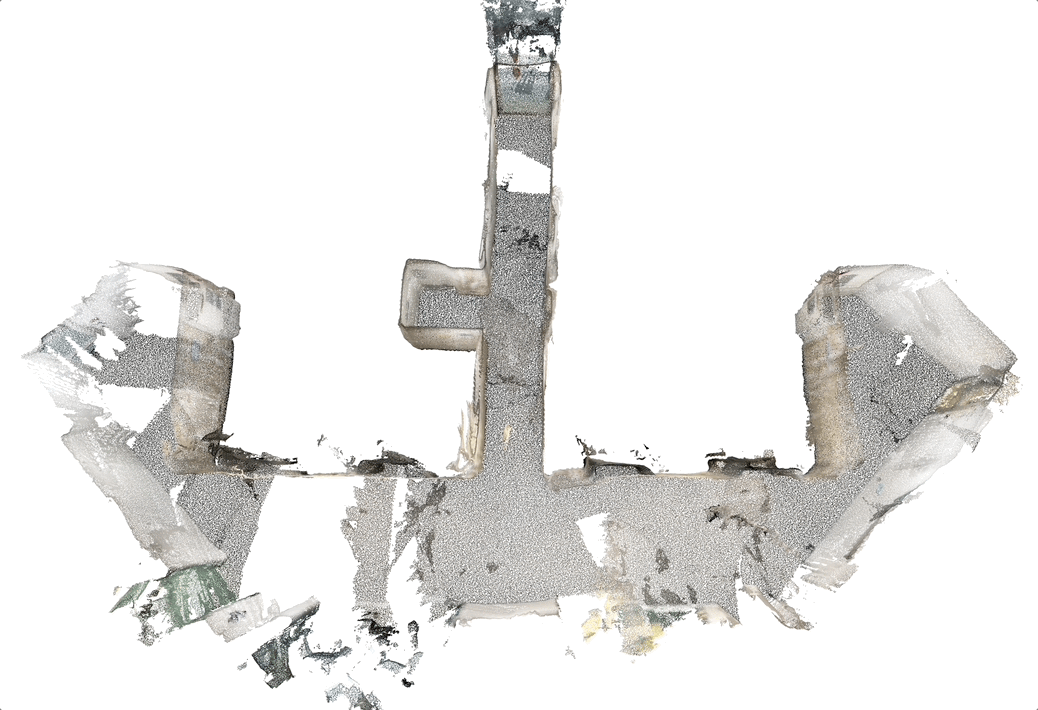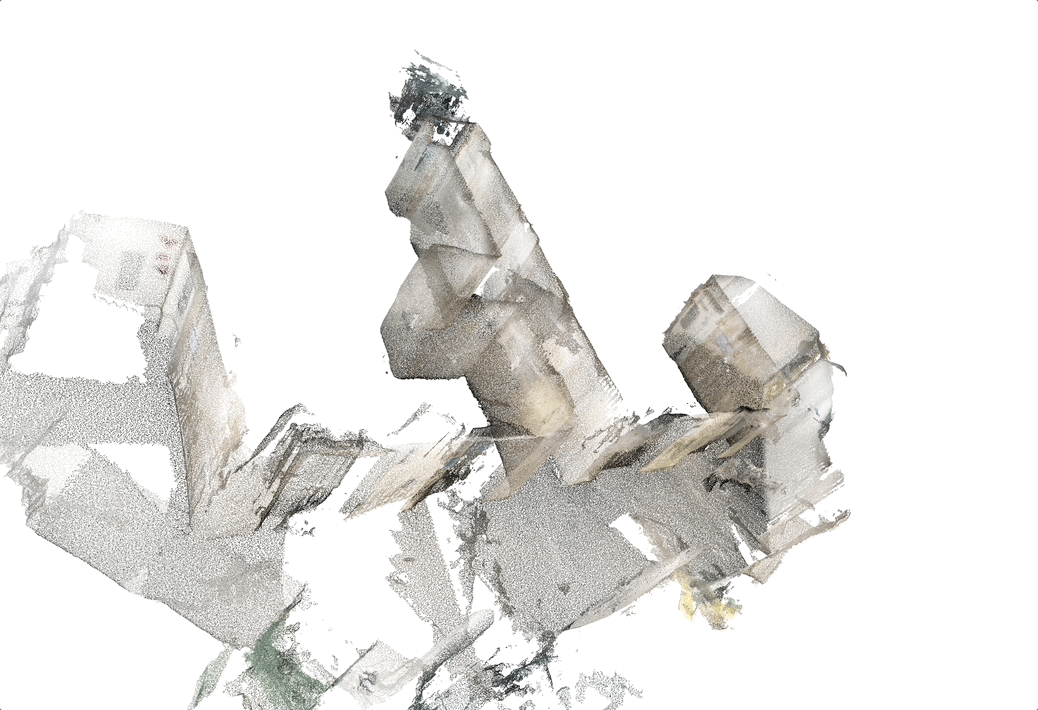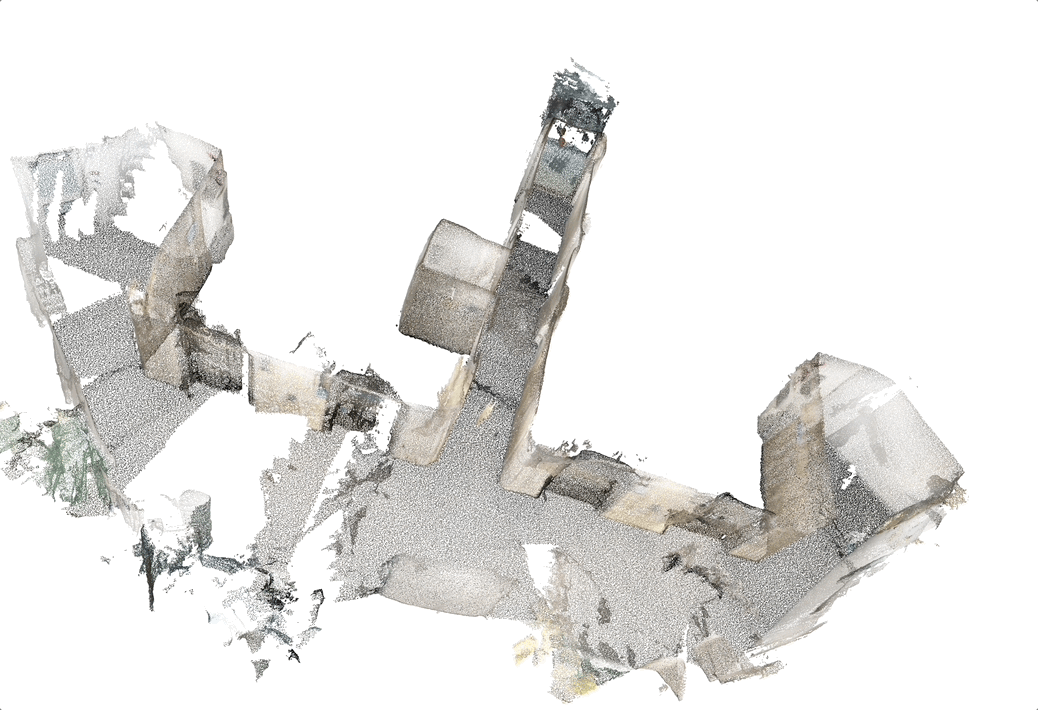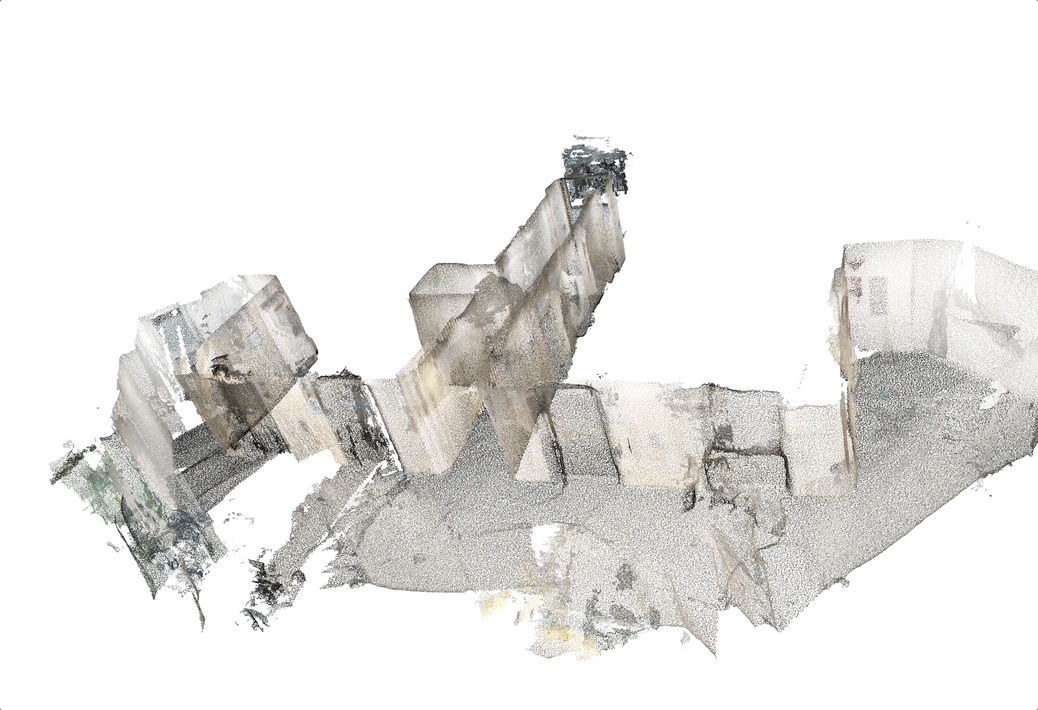 |
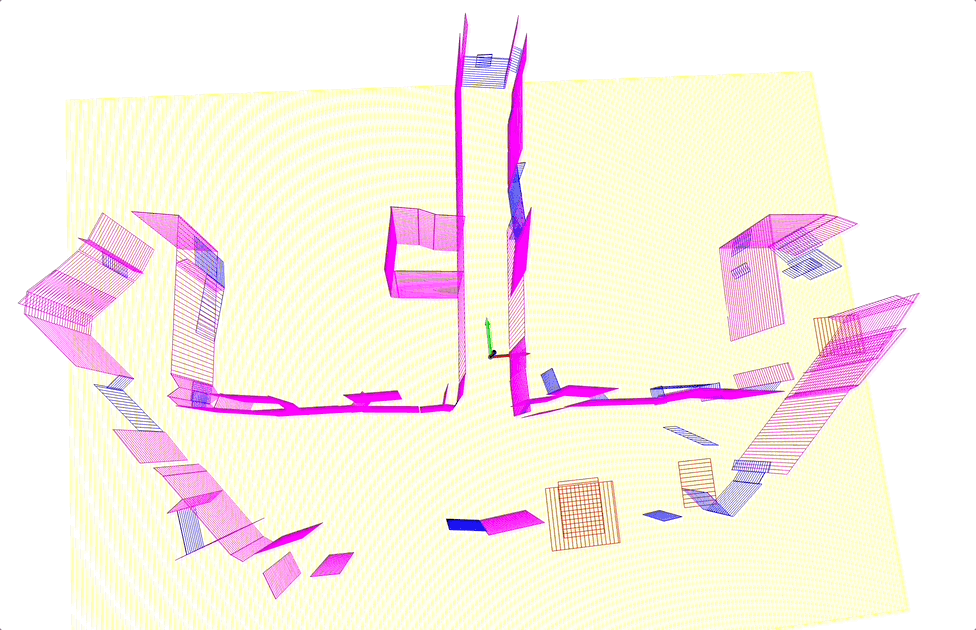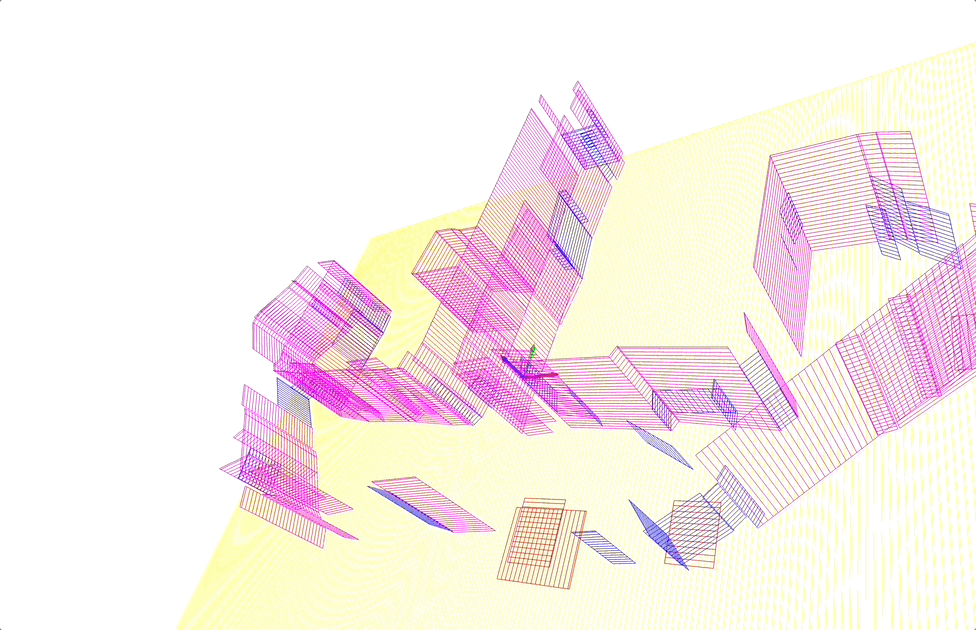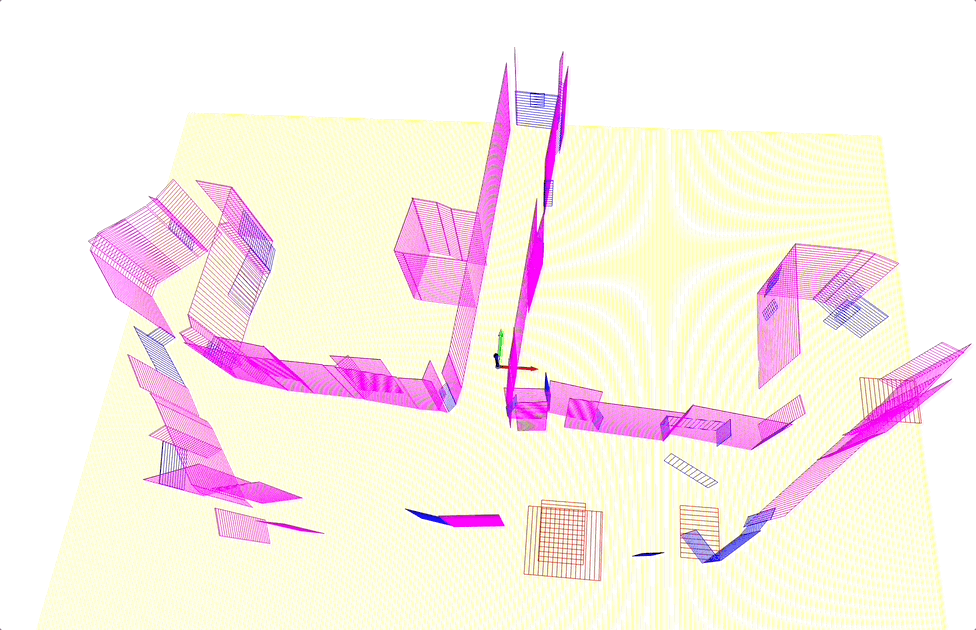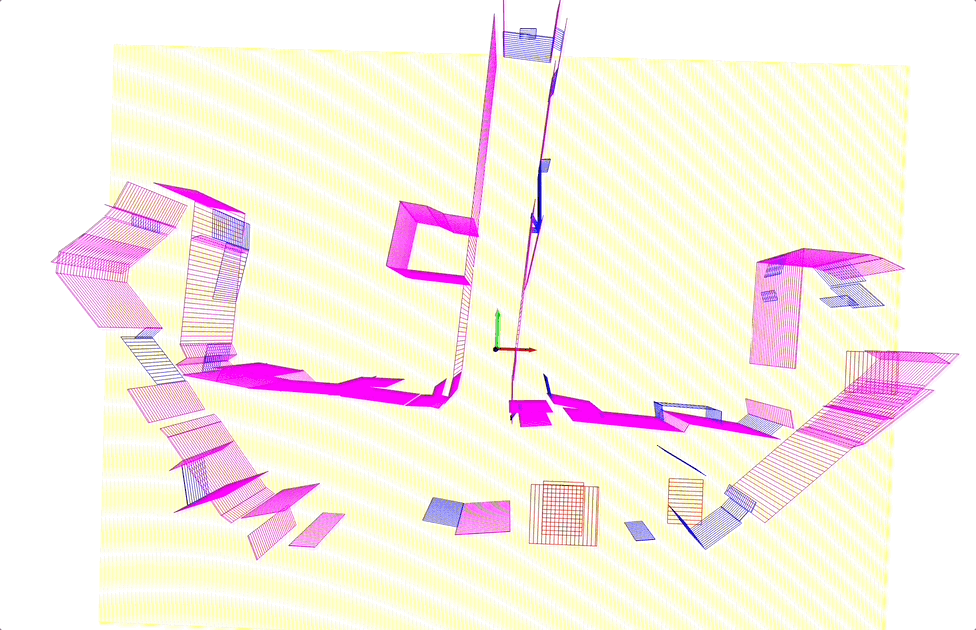 |
 |
 |
AR (Augmented reality) Cloud
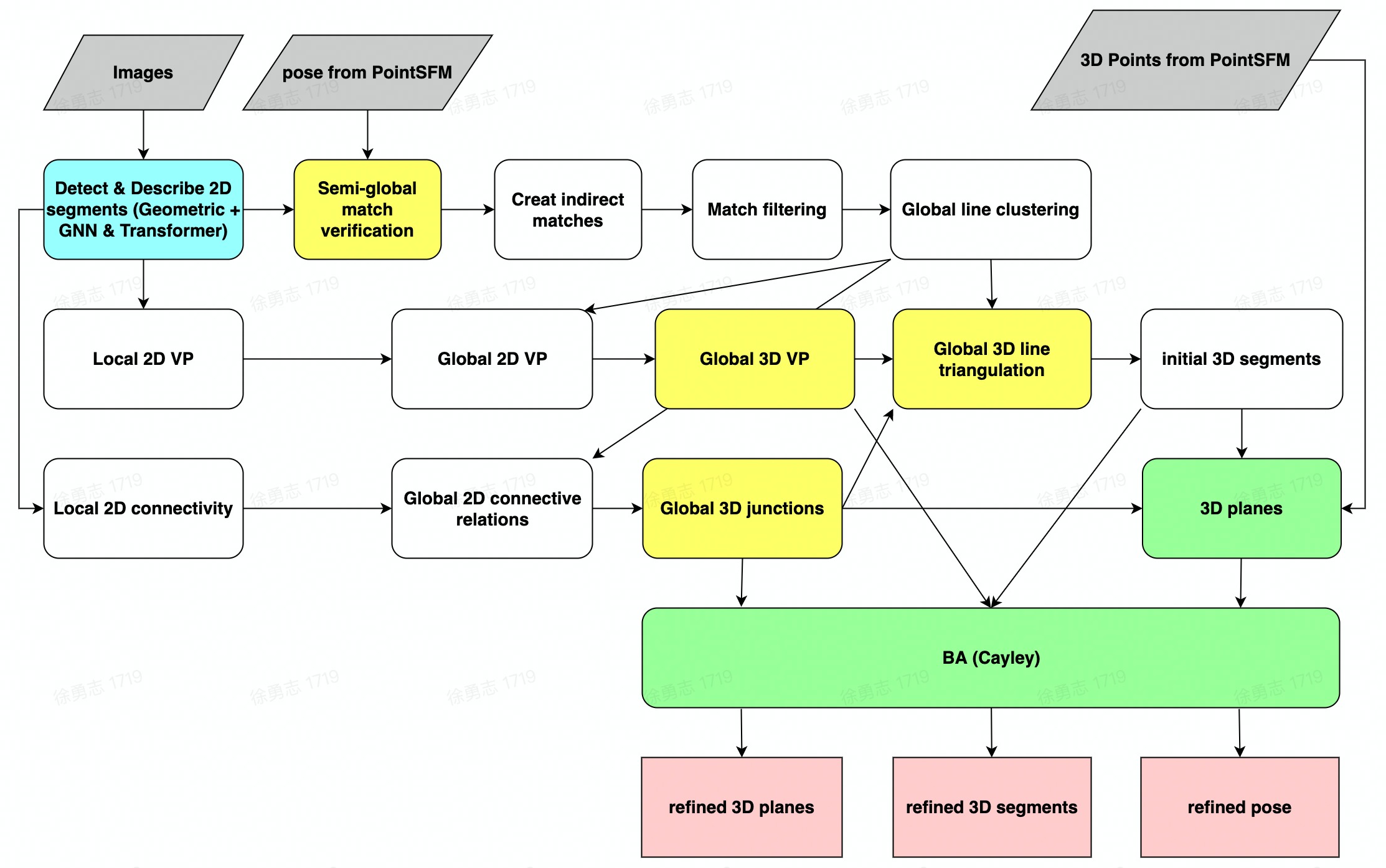
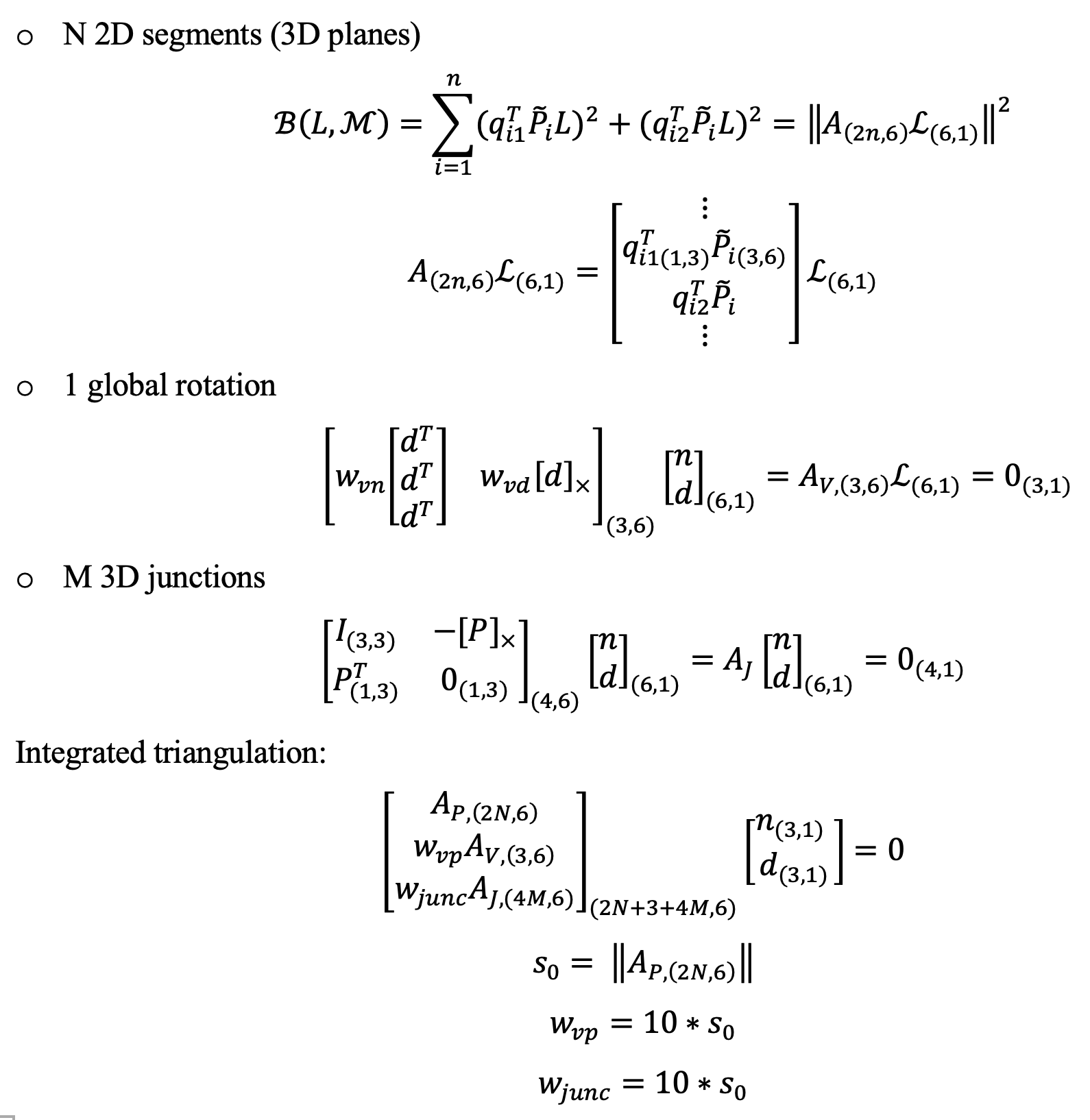
Structure from motion (SFM) of 3D line map
Key contributions:
- A novel 3D mapping pipeline.
- Multi-view triangulation using Plucker representation.
- No Manhattan assumption
 |
 |
 |
 |
| 3D point cloud |  |
 |
| 3D line cloud | 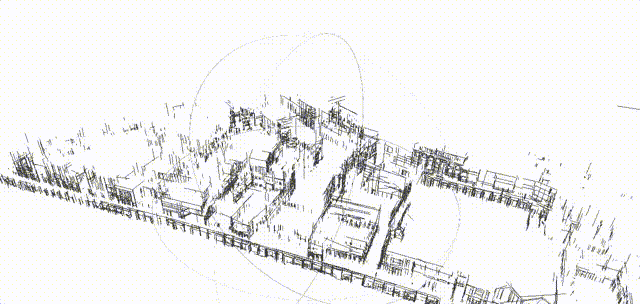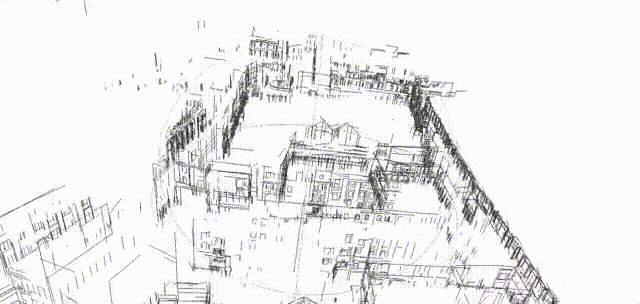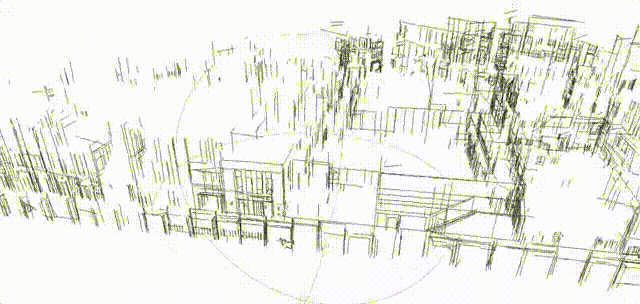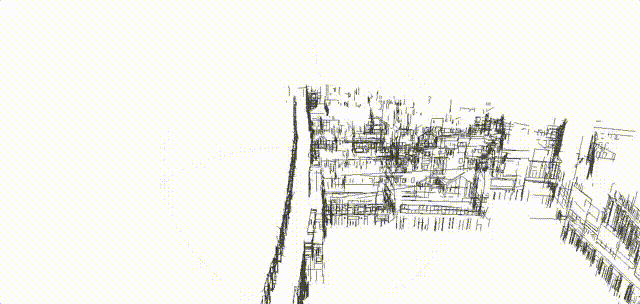 |
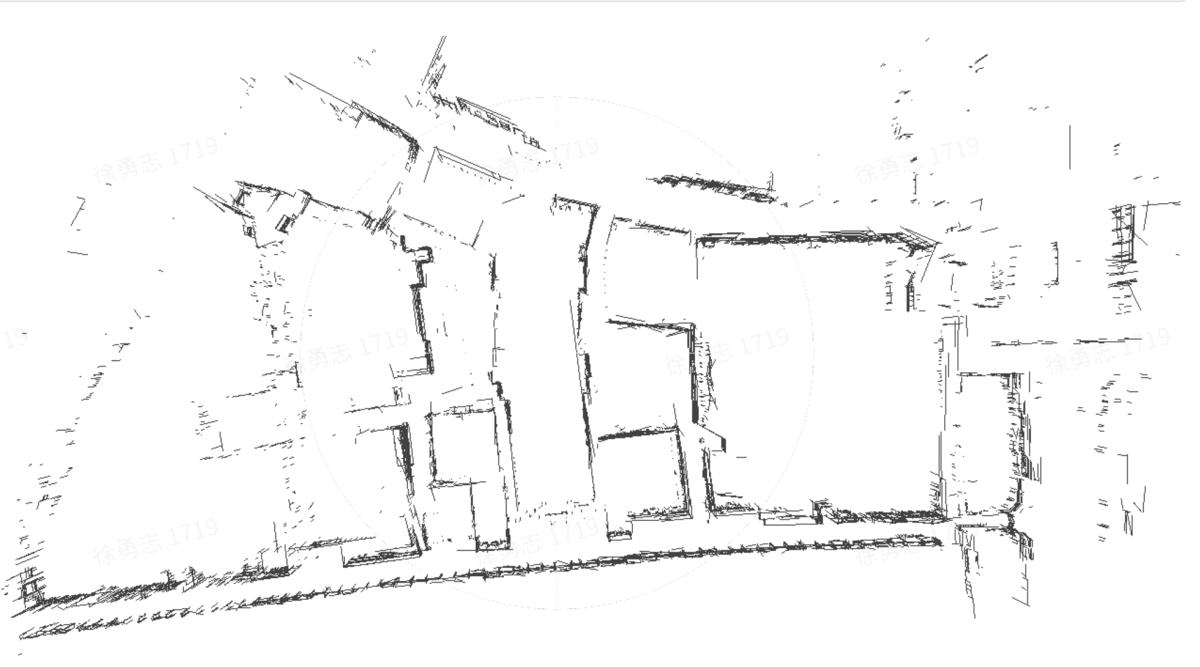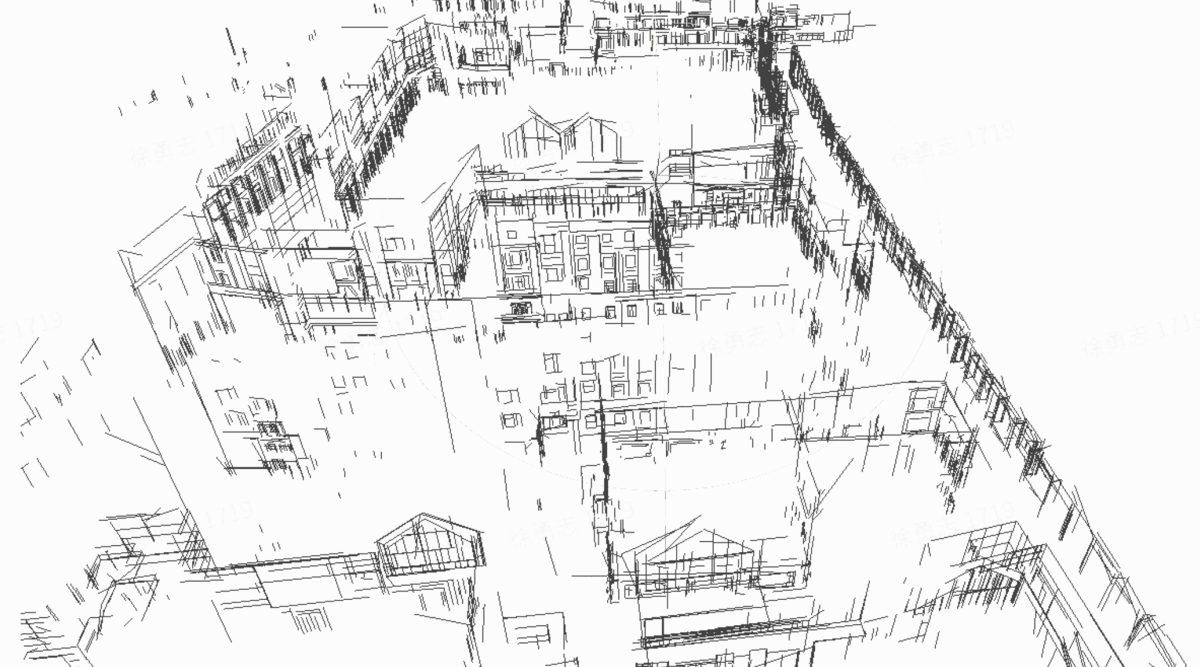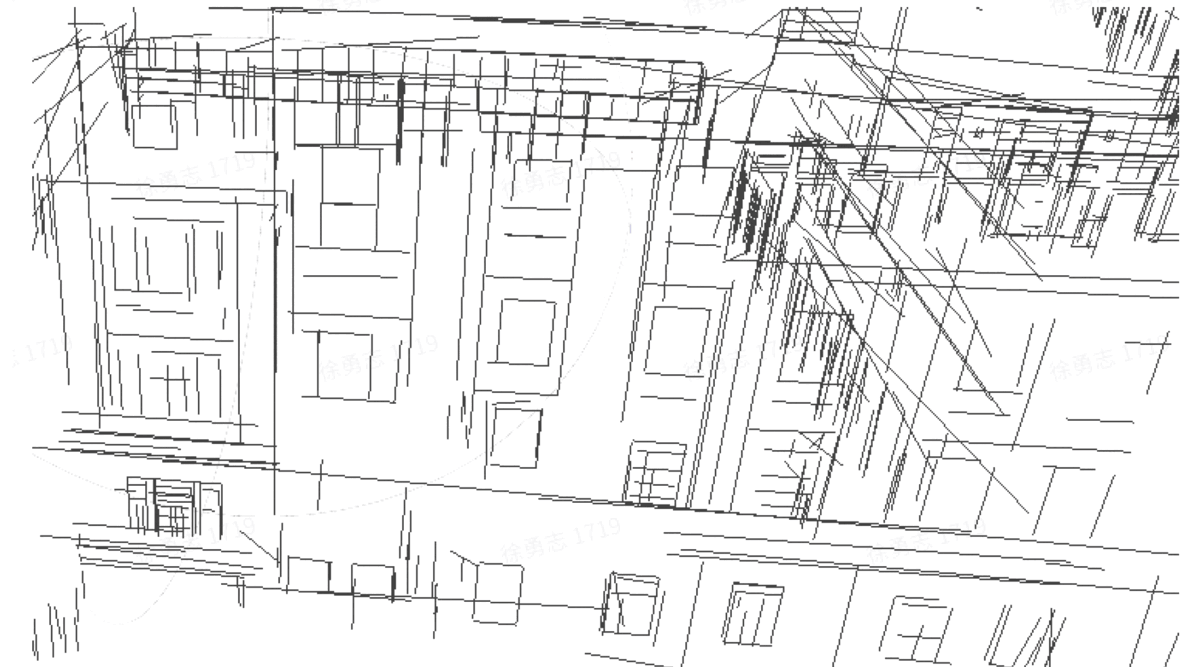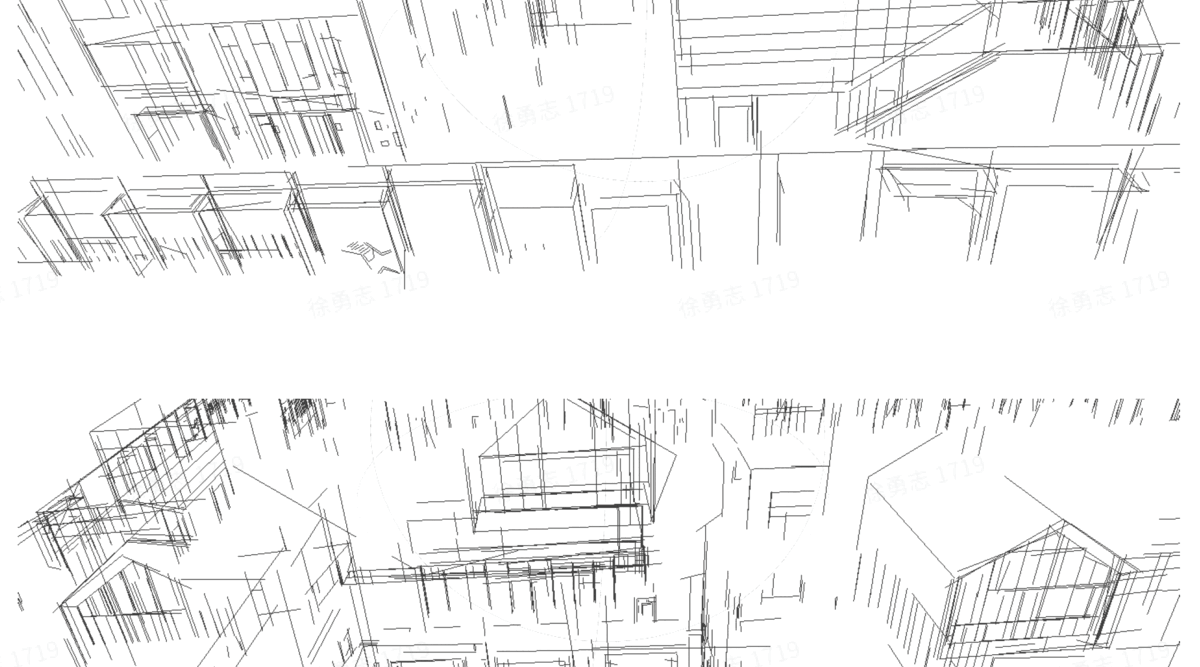 |
| Reprojections |  |
 |
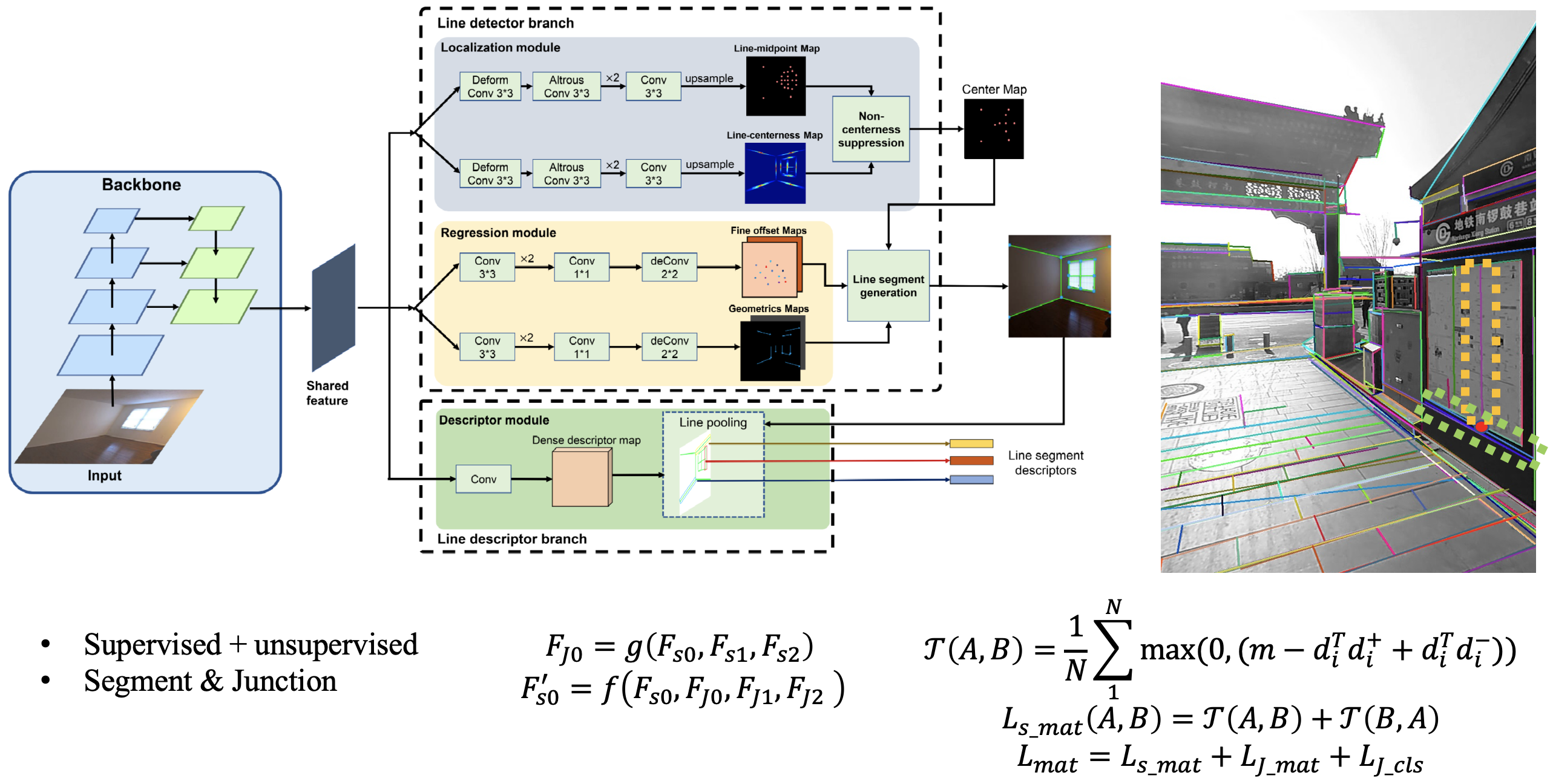
Visual positioning system combining features of point and line
Key contributions:
- A novel geometric & descriptor fused line matching approach based on coarse VPS pose.
 |
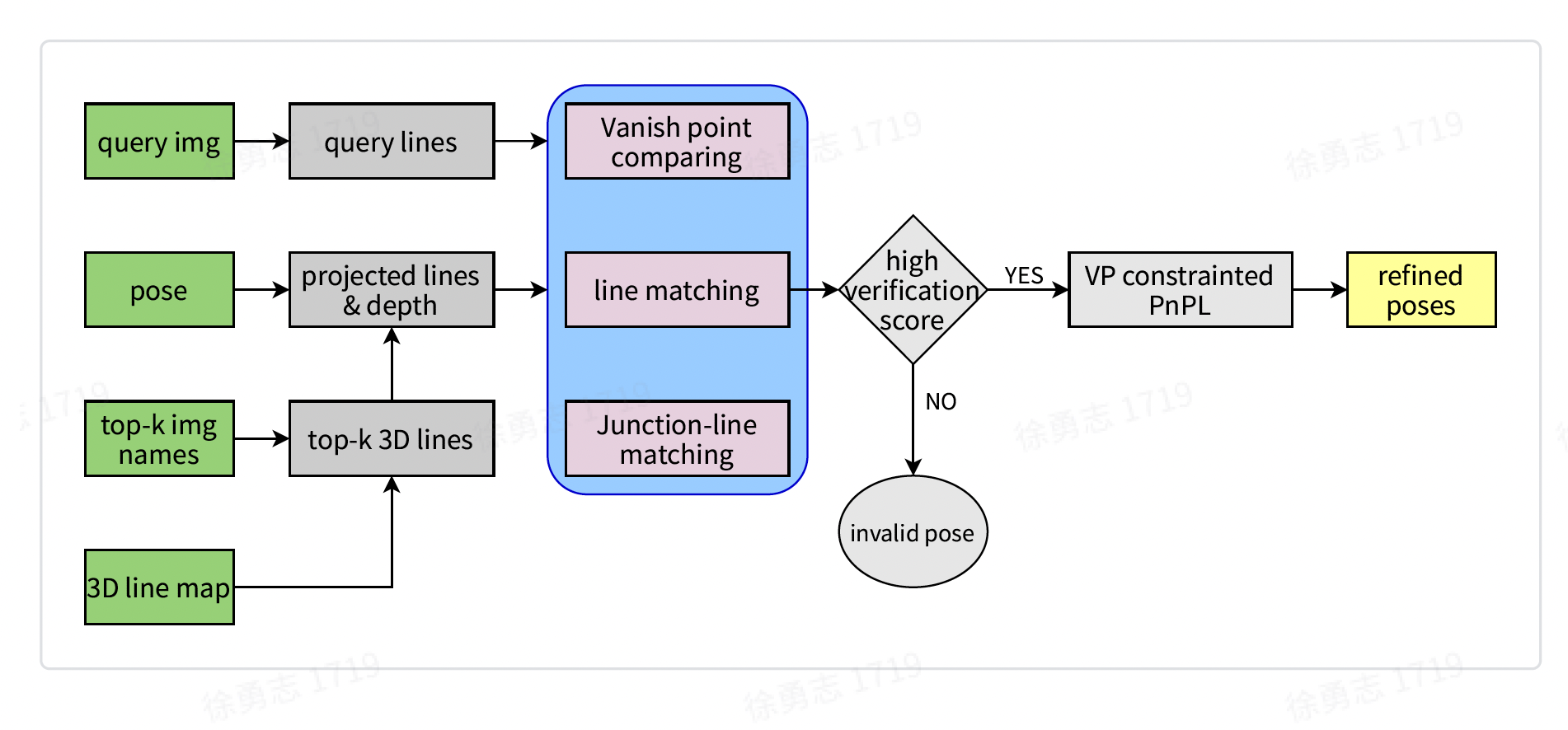 |
| I proposed a new approach of pose refinement by combing deep features of points and lines. The 1st contribution is a structure-aware line detector \& descriptor network, which jointly matches lines and junctions locally. The 2nd one is a fused PnPL-based pose estimator combing line-matching, junction-matching and vanishing points. The localization accuracy (within 1m) has been improved from 91\% to 96\% compared with using points only. |  |
SuperPoint
I improved the open implementation of SuperPoint which achieve similar performance of the official model. The recall of MagicLeap can achieve 0.42. However, the recalls of pretrained model of TF_SP and PyTorch_SP are both around 0.145. I have improved the recall of PyTorch_SP to 0.41.
- Holography augmentation using Thesesus (https://github.com/facebookresearch/theseus)
- Small rotation (15 to 30 degree)
- Using pseudo GT generated by MagicLeap-SP, instead of MagicPoint in Pytorch_SP
- An implementation of homograph adaptation based on the original paper, combing within-scale and across-scale.
- Use the Recall to evaluate the performance following “An Evaluation of Feature Matchers for Fundamental Matrix Estimation”.
3D surface detection from a single view
Multiple 3D surfaces are detected from a single view.
- No Manhattan assumption
- Unknown camera models
- 3D normal accuracy > 97% in real world images (around 60% accuracy achieved by SOTA learning and handcrafted methods.)

Wrap virtual materials on the 3D surfaces:
- Fully automated and real-time generation of multiple 3D planes from a single view.
- The layout of multiple planes are optimized based on the scores and distribution of 3D planes.
 |
 |
Intelligent advertisement placement
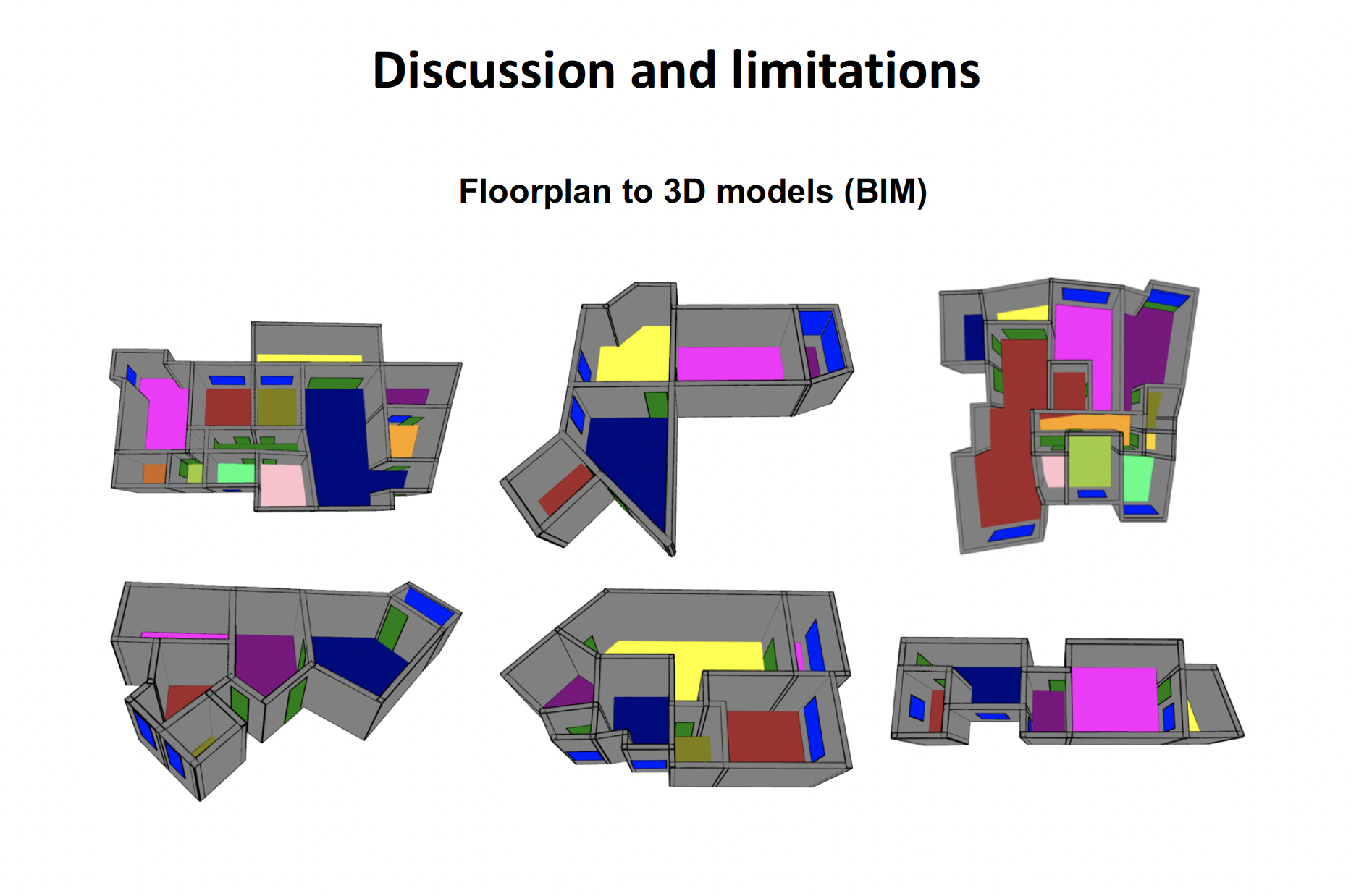
Scan-to-BIM
- Input: registered point cloud
- Output: building information models (BIM), which are 3D objects with semantic and structural information.
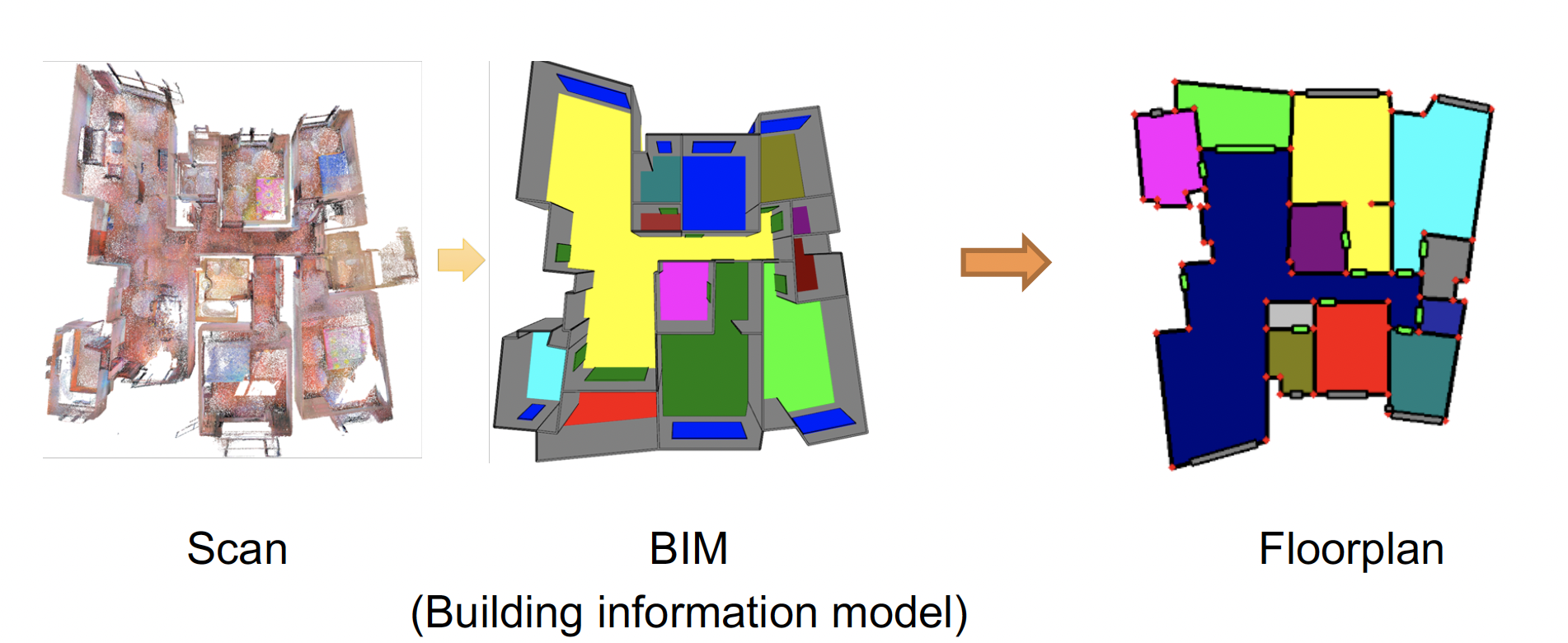
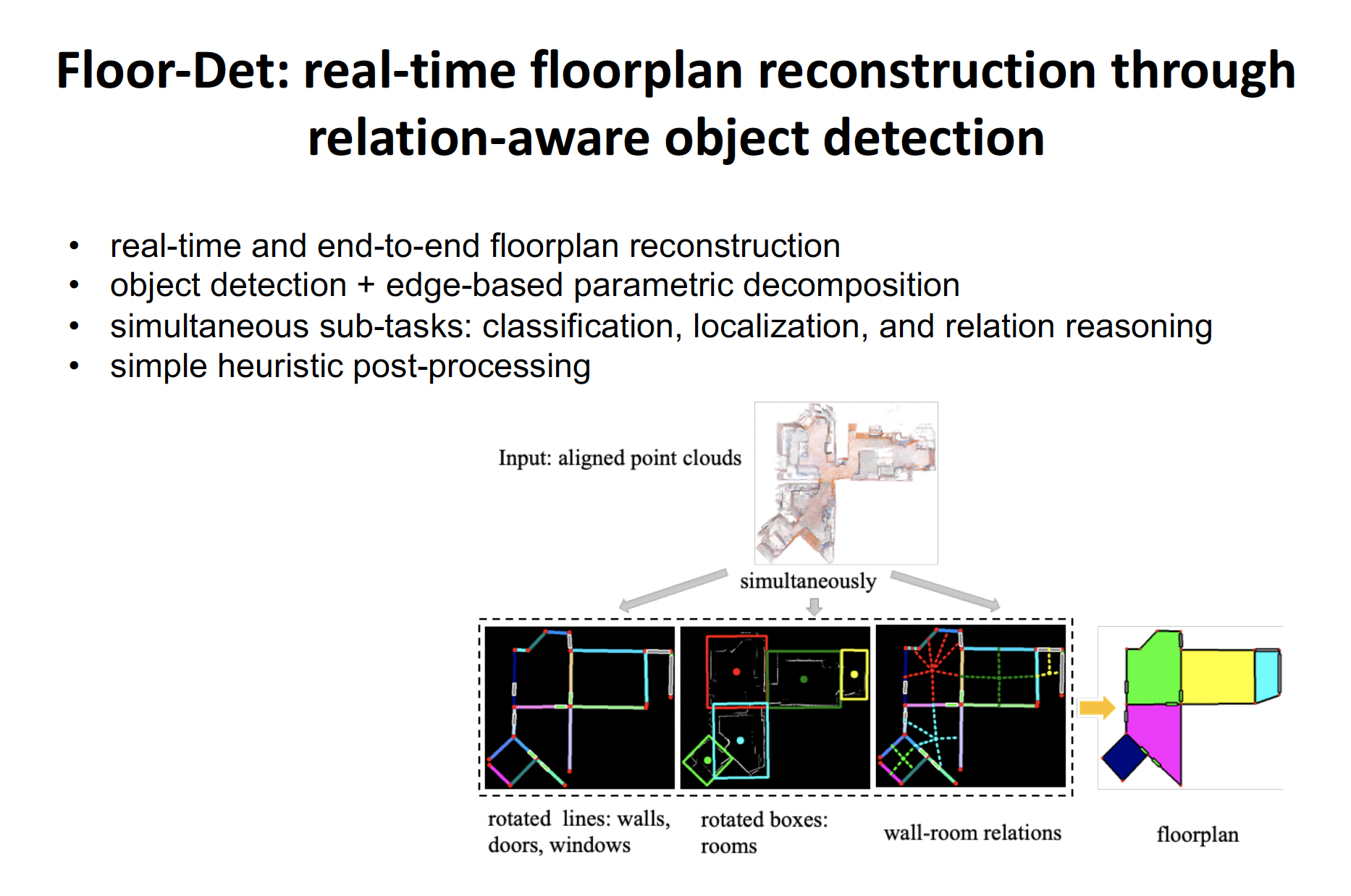
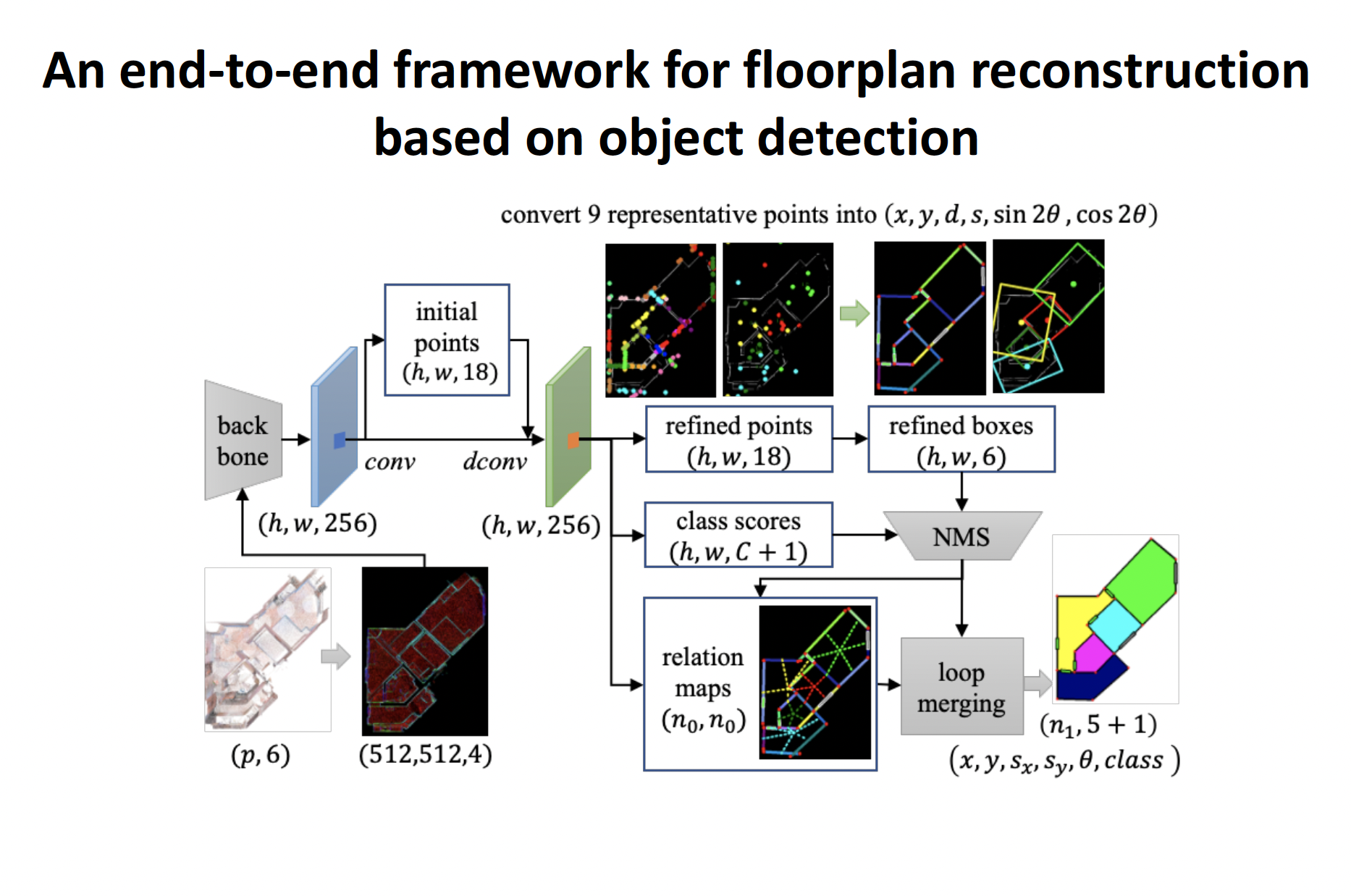
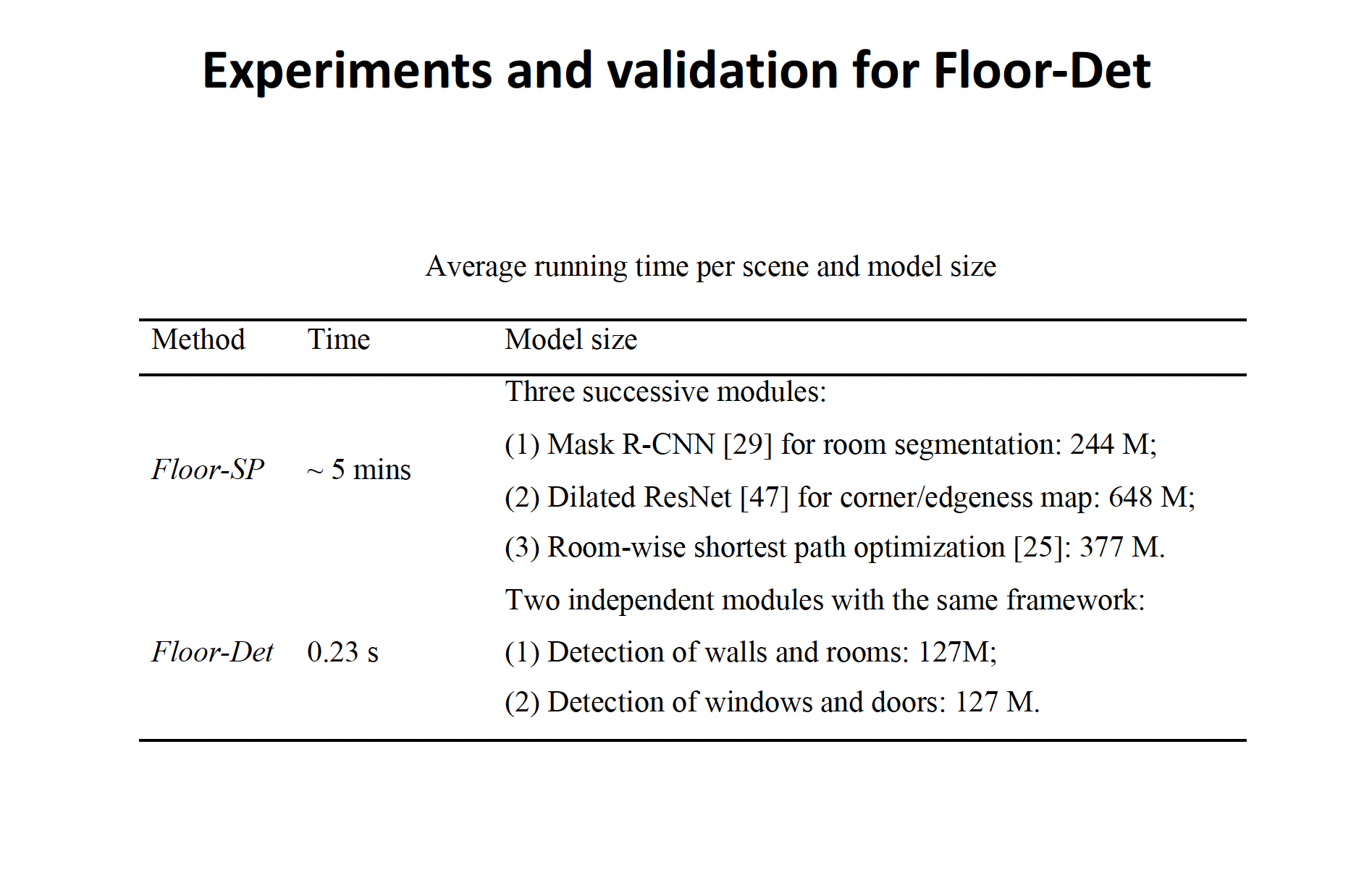
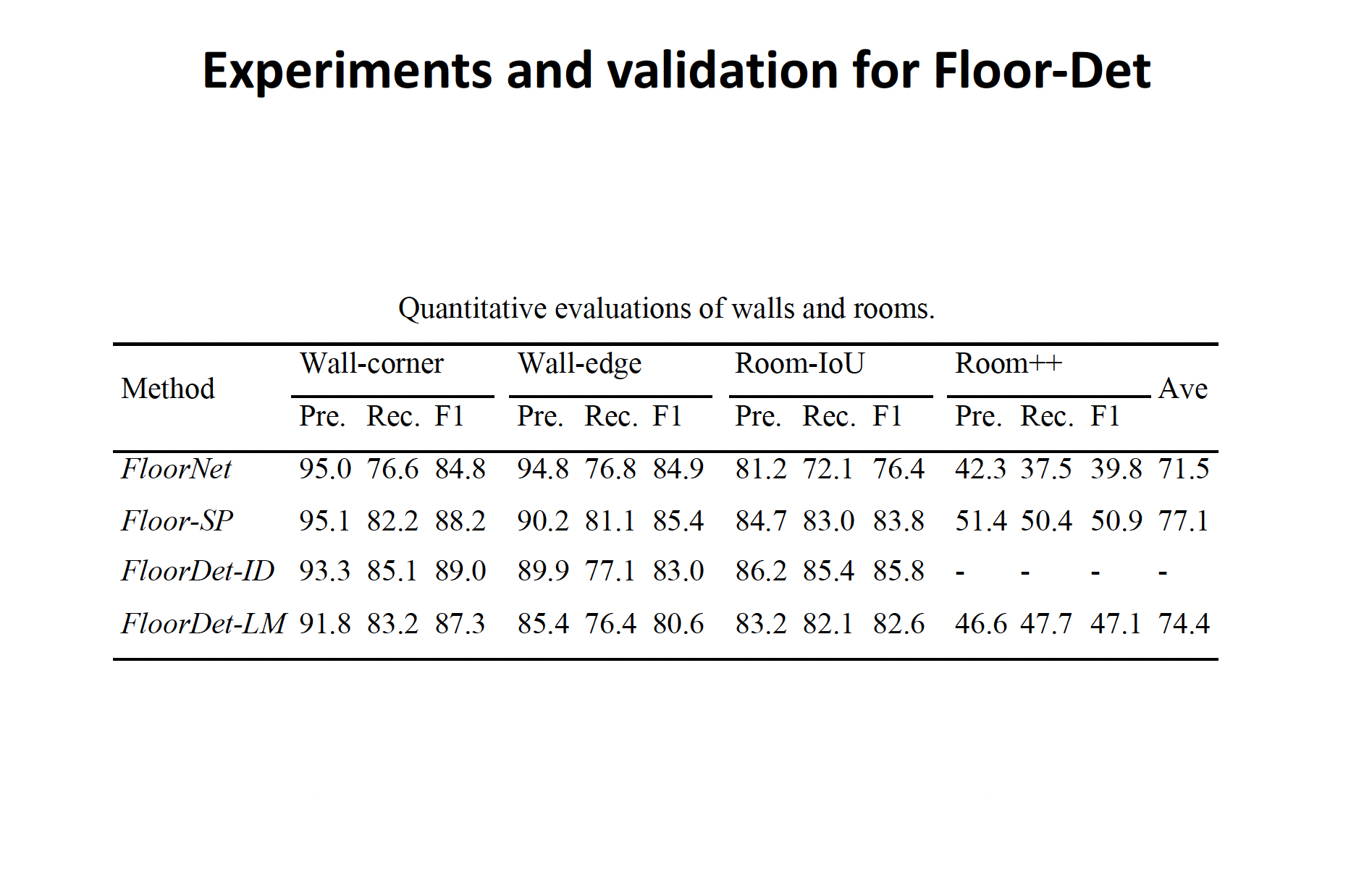
FloorDet
 |
 |
 |
 |
 |
 |
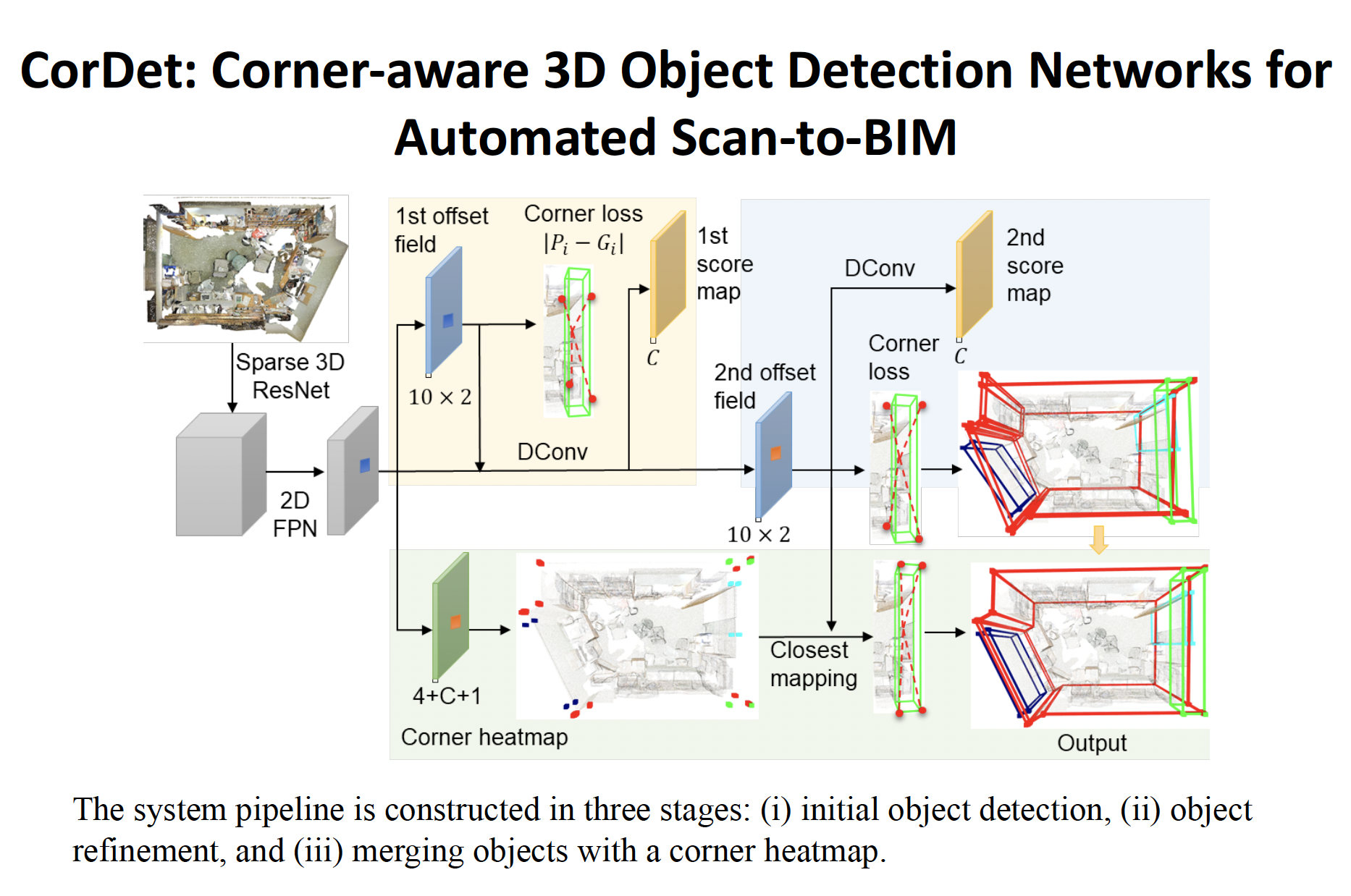
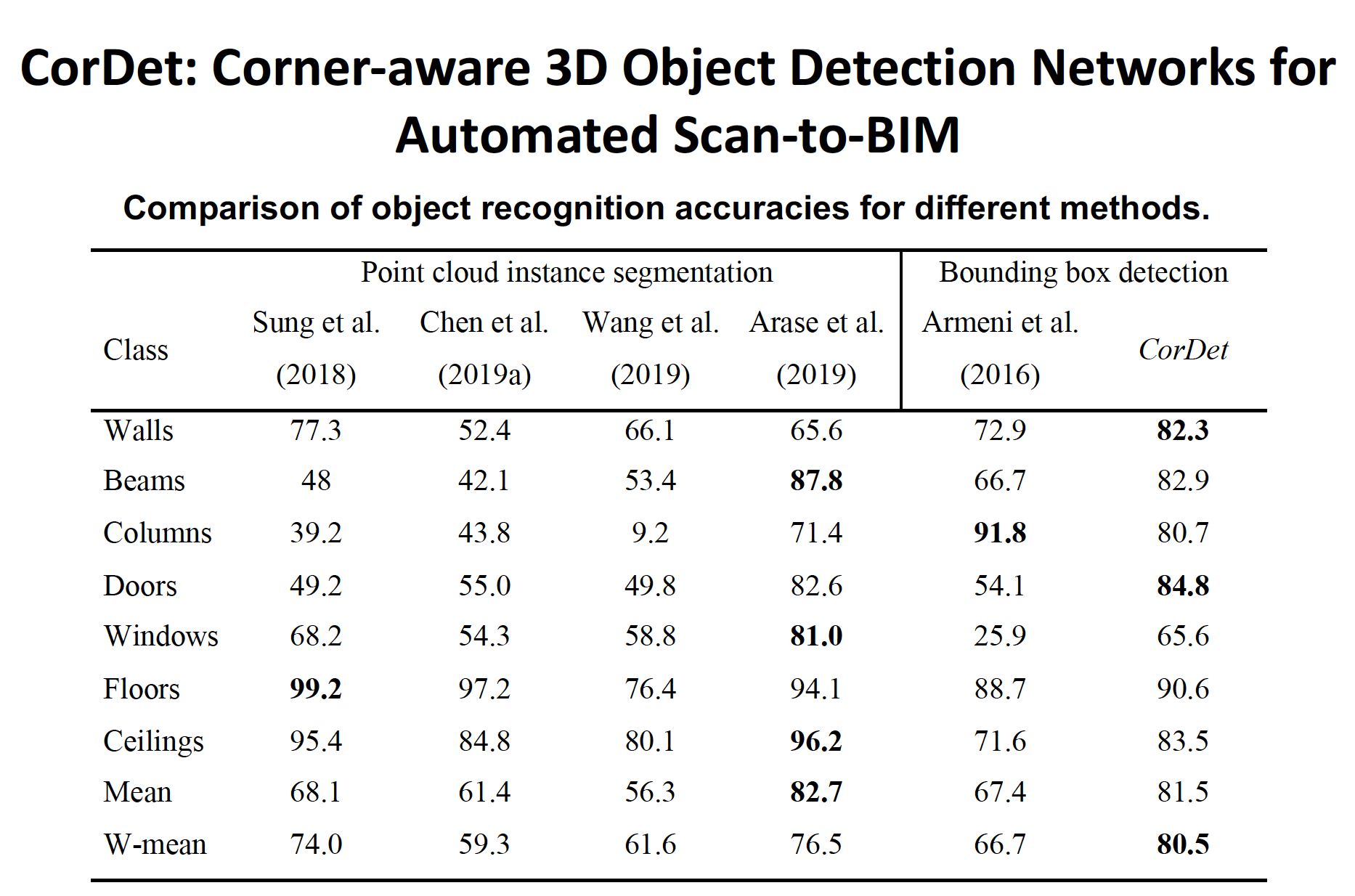
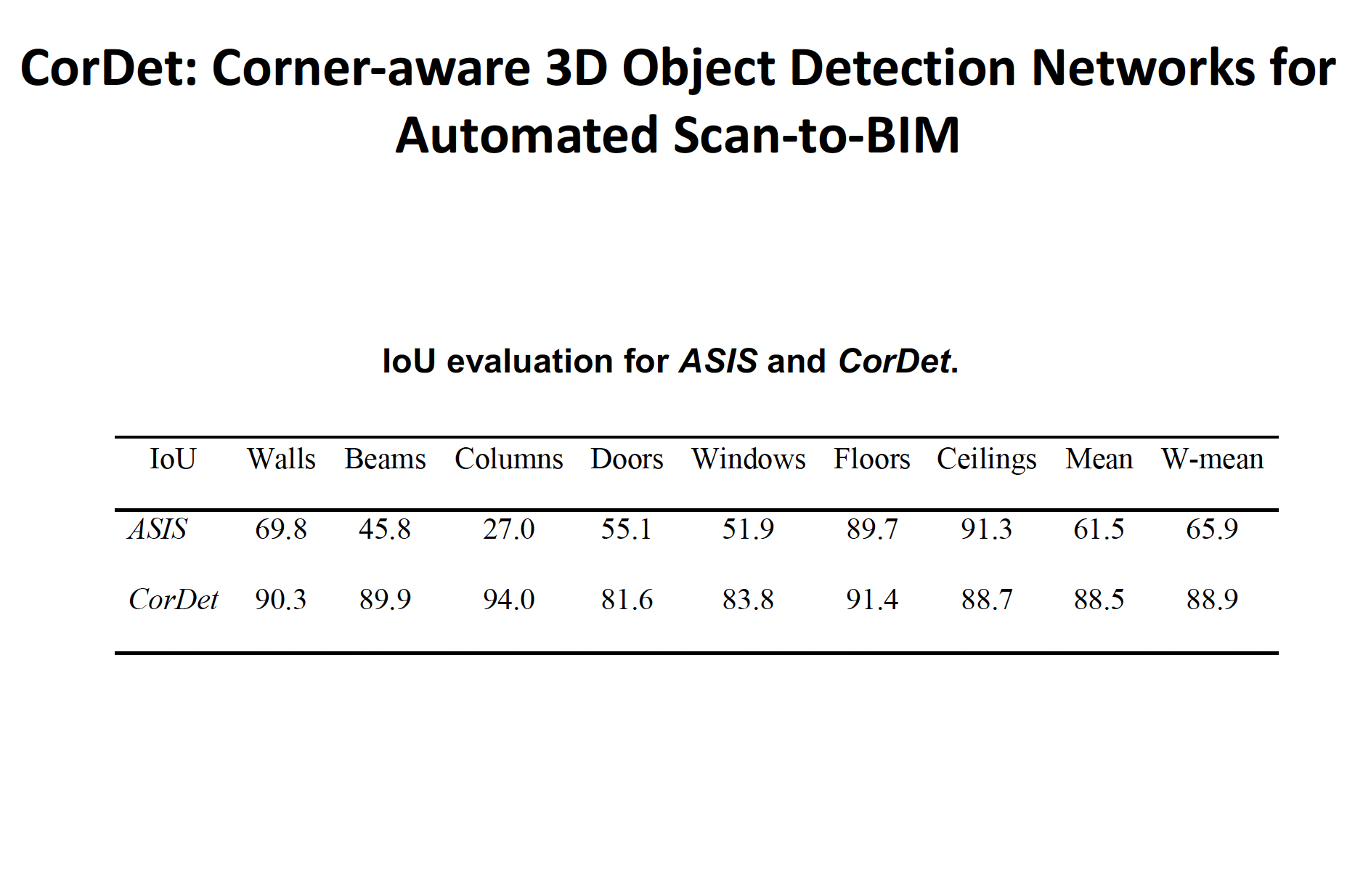
CorDet
 |
 |
 |
 |
 |
 |